Mastering Statistical Analysis in Engineering with R Programming
Introduction: Statistical analysis is a cornerstone of engineering, providing insights into complex systems, validating hypotheses, and guiding decision-making processes. R programming language, with its rich ecosystem of statistical packages and libraries, has become a preferred tool for conducting statistical analysis in various domains, including engineering. In this comprehensive guide, we will explore the fundamentals of programming in R for statistical analysis in engineering, covering essential concepts, practical techniques, and advanced methodologies.
Section 1: Understanding R Programming
1.1 Overview of R: R is an open-source programming language and environment specifically designed for statistical computing and graphics. It provides a wide range of functions and packages for data manipulation, visualization, and statistical analysis, making it an ideal choice for engineers seeking to leverage statistical techniques in their work.
1.2 Key Features of R:
- Data Handling: R offers powerful data structures and functions for importing, manipulating, and transforming data, including vectors, matrices, data frames, and lists.
- Statistical Functions: R encompasses a vast array of statistical functions and algorithms for descriptive statistics, hypothesis testing, regression analysis, time series analysis, and more.
- Graphics and Visualization: R provides high-quality graphics and visualization capabilities through packages like ggplot2, allowing engineers to create informative plots and charts to visualize data and analysis results.
- Extensibility: R’s extensibility through packages allows users to access a wide range of specialized statistical methods, machine learning algorithms, and domain-specific tools tailored to engineering applications.
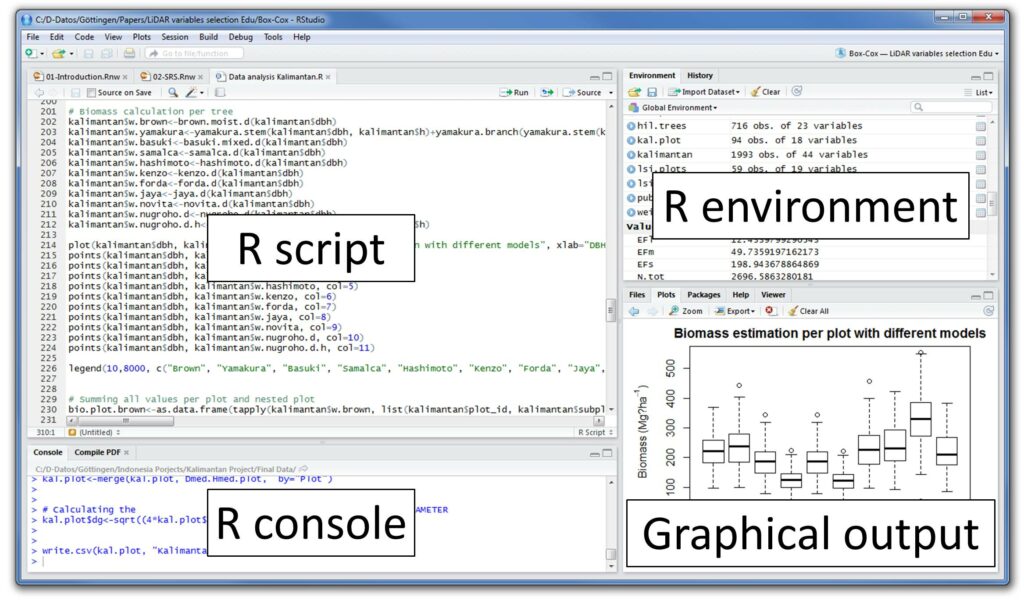
1.3 Getting Started with R: Engineers new to R can start by installing R and an integrated development environment (IDE) such as RStudio, which provides a user-friendly interface for writing, executing, and debugging R code. Learning resources such as online tutorials, books, and community forums can help beginners grasp the basics of R programming and statistical analysis.
Section 2: Data Handling and Manipulation
2.1 Importing Data: R offers multiple functions and packages for importing data from various sources, including spreadsheets, databases, text files, and web APIs. Engineers can use functions like read.csv(), read.xlsx(), read.table(), and readr package to import data into R for analysis.
2.2 Data Exploration: Before performing statistical analysis, it’s essential to explore and understand the structure of the data. R provides functions like summary(), str(), head(), and tail() to examine data attributes such as dimensions, variable types, summary statistics, and sample observations.
2.3 Data Manipulation: R’s powerful data manipulation capabilities enable engineers to clean, transform, and reshape data to prepare it for analysis. Functions from packages like dplyr, tidyr, and reshape2 allow users to filter rows, select columns, group data, pivot tables, and perform other common data manipulation tasks efficiently.
Section 3: Statistical Analysis Techniques
3.1 Descriptive Statistics: Descriptive statistics summarize and describe the characteristics of a dataset, including measures of central tendency, dispersion, and distribution. R provides functions like mean(), median(), sd(), quantile(), and hist() for calculating and visualizing descriptive statistics.
3.2 Hypothesis Testing: Hypothesis testing is a fundamental statistical technique for making inferences about population parameters based on sample data. R offers functions for conducting various hypothesis tests, such as t-tests, chi-square tests, ANOVA, and non-parametric tests, enabling engineers to assess the significance of observed differences or relationships in data.
3.3 Regression Analysis: Regression analysis is used to model the relationship between one or more independent variables and a dependent variable. R provides functions for fitting linear regression, logistic regression, polynomial regression, and other regression models, allowing engineers to analyze relationships, make predictions, and assess model accuracy.
3.4 Time Series Analysis: Time series analysis involves analyzing and forecasting data collected over time, such as sensor measurements, financial data, and environmental variables. R’s time series packages like forecast, zoo, and xts offer functions for time series decomposition, forecasting, seasonal adjustment, and anomaly detection, facilitating robust analysis of temporal data.
Section 4: Advanced Techniques and Applications
4.1 Design of Experiments (DOE): Design of experiments is a methodology for systematically planning and conducting experiments to optimize processes, improve product quality, and identify influential factors. R’s DOE packages like DoE.base, FrF2, and AlgDesign provide functions for designing factorial, fractional factorial, and response surface experiments, enabling engineers to efficiently explore complex parameter spaces and optimize system performance.
4.2 Reliability Analysis: Reliability analysis assesses the probability of system failure or component malfunction over time, helping engineers design reliable and resilient systems. R’s reliability packages like survminer, survival, and flexsurv offer functions for survival analysis, hazard modeling, reliability estimation, and accelerated life testing, supporting rigorous reliability assessments in engineering applications.
4.3 Machine Learning: Machine learning techniques complement traditional statistical methods by enabling engineers to build predictive models and extract insights from large and complex datasets. R’s machine learning packages like caret, randomForest, and glmnet provide algorithms for classification, regression, clustering, dimensionality reduction, and ensemble learning, empowering engineers to tackle diverse engineering problems, from predictive maintenance to fault detection.
Section 5: Best Practices and Tips
5.1 Documentation and Reproducibility: Documenting code and analysis procedures is essential for ensuring transparency, reproducibility, and collaboration in engineering projects. Engineers should adopt best practices such as commenting code, creating reproducible scripts with R Markdown, and version control with tools like Git to maintain organized and well-documented workflows.
5.2 Validation and Verification: Validating and verifying statistical models and analysis results is critical for ensuring their accuracy and reliability. Engineers should assess model assumptions, evaluate goodness-of-fit, and perform sensitivity analysis to validate statistical models and verify analysis outcomes before drawing conclusions or making decisions based on them.
5.3 Continuous Learning and Professional Development: Statistics and data analysis are vast and evolving fields, requiring continuous learning and professional development to stay abreast of new methodologies, tools, and techniques. Engineers should invest in ongoing training, attend workshops and conferences, and engage with online communities to enhance their statistical analysis skills and expand their knowledge base.
Conclusion: Programming in R for statistical analysis opens up a world of possibilities for engineers, empowering them to harness the power of data-driven insights and make informed decisions in engineering practice. By mastering R’s capabilities for data handling, statistical analysis, and visualization, engineers can analyze complex systems, identify patterns, and extract actionable insights to drive innovation and optimize performance across diverse engineering domains. With a commitment to continuous learning, best practices, and interdisciplinary collaboration, engineers can leverage R programming to tackle real-world engineering challenges and contribute to the advancement of science and technology.